訂閱 Facebook Group 的訊息:自建 RSS 伺服器
feedly 是一款 Web RSS 訂閱服務,自從 Google Reader 2013 年停止服務後,我就一直使用它,但隨著社群媒體像 Facebook 或 Twitter 流行,訊息的樣貌也改變很多,最痛苦的就是在 Facebook 跟人互動,結果這些訊息都要透過 Facebook 動態來 Follow,等同於變相洗版,何況 Facebook 有自己的演算法,會篩掉它認為你沒興趣的訊息。
這幾天被 Facebook 洗版洗到受不了,外加漏掉一則重要訊息,終於忍無可忍決定找一個新的訂閱方式,但偏偏 Facebook 本身不提供 RSS 訂閱服務,只好土法煉鋼,自己想辦法。
本文會用 tweeper + GCP + feedly 來完成對 Facebook 公開頁面的訂閱。讓這些消息能更好地被管理。
Fetch RSS
要訂閱消息,就要有消息來源,我們用 tweeper 來抓取 Facebook 並轉換成 RSS,這是一款 Linux 工具,首先安裝
sudo apt-get install tweeper使用方式非常簡單,在後面跟著 Facebook 的公開頁面
tweeper https://www.facebook.com/groups/cloudnative.tw/然後在 stdout 中,就能看到抓取的資料
<?xml version="1.0"?>
<rss version="2.0" xml:base="https://facebook.com">
<channel>
<generator>Tweeper</generator>
<title>Biz</title>
...RSS 使用 XML 格式來發佈消息,這個消息文件稱為 RSS feed。RSS Reader 就是抓取這些 feeds 的 URL 來訂閱。
Install Apache
抓取下來的 feed 要給外網存取,因此需要有個網頁伺服器,我們使用最常見的 apache
sudo apt-get install apache2安裝好後,apache 會用 80 port 提供 HTTP 服務,相關的文檔放在
/var/www/
在瀏覽器中輸入對應 IP,可以看到 apache 的畫面

當現在有一份文件需要對外提供時,可以放到 /var/www 中,外部就能得到這份文件。
Register a Domain Name
因為資安考量,我們不希望將內網曝露到外網中,想在外部架設新的 Server 來提供服務,為了方便 RSS Reader 能找到 Server Address,還需要有個 Domain Name,也就是平常說的網址,這個網址能對應到自行架設的 Server Address。Domain Name 可以向供應商購買,像 Google Domains 就有提供這個服務,價格是 20$/Year
但我們先用免費的 Domain 來測試,交大有無償提供這項服務
註冊並登入後,在網域管理的標籤下,可以新增子網域,輸入自定義的網域名稱
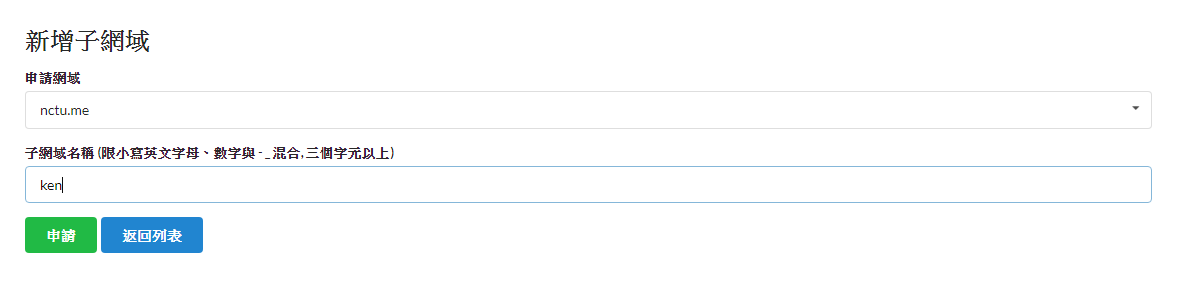
並在 DNS 管理中新增紀錄,輸入名稱與 IP,即可完成申請。如果已經有 GCP 的,可以在 IP 填入 GCP 的 External Address,如果還沒有,先進行下一步,取得 GCP 的 IP。
Set GCP
申請好網域後,就是要架 Server 了。外部 Server 可以用 GCP 架設,具體流程是進入 GCP,開好 VM,安裝需要的軟體,如果不知道怎麼使用 GCP,可以參考前面的文章,GCP 也有提供 apache 的安裝說明
開通 VM 時,要記得將 Firewalls 的 Allow HTTP traffic、Allow HTTPS traffic 兩項打勾,GCP 才能提供 HTTP 跟 HTTPS 的服務。
VM 設完來建立工作目錄。在家目錄底下建一個 rssfeed 資料夾,將輸出的 RSS feed 放到這個資料夾中。接著到 /var/www/html 下創建一個連結到 rssfeed,這樣一來,即使沒有管理者權限,也能在家目錄下管理檔案
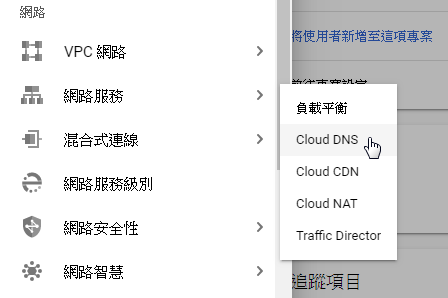
mkdir rssfeed && cd rssfeedtweeper https://www.facebook.com/groups/cloudnative.tw > cloudnative.tw.xmlcd /var/www/htmlsudo ln -s ~/rssfeed ./rssfeed完成後還要修改網路設定,到網路服務點選 Cloud DNS
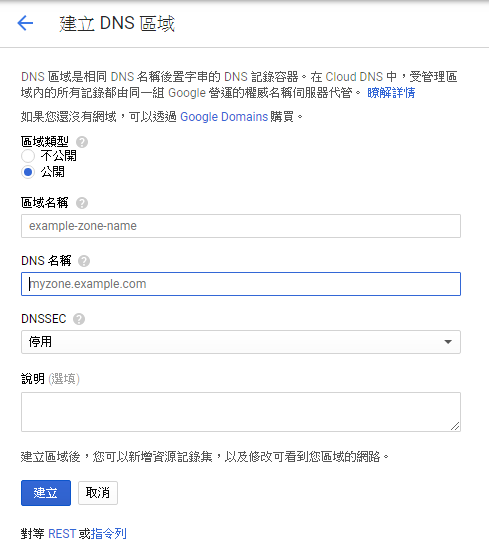
建立區域,將 DNS 名稱,就是前面步驟申請的網域名填入
外部就可以用 URL 來使用 GCP 的服務了。
Subscribe RSS
現在用 feedly 訂閱剛剛製作完成的 RSS feed,打開 feedly,點選側欄的「+」號,進入探索頁面
在搜尋欄中填入 RSS 的網路位置,例如
http://example.nctu.me/rssfeed/cloudnative.tw.xml
就能在 FEEDS 的訂閱項目中看到訊息啦
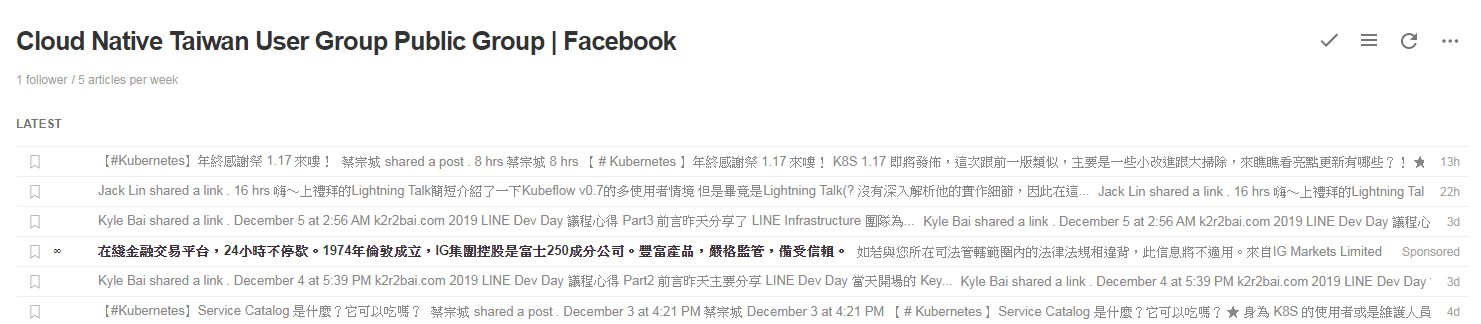
是不是很有成就感!
Update RSS Periodically
雖然能用 feedly 訂閱 RSS 了,但 RSS 需要定期更新,feedly 才有最新的資料能抓。我們這邊利用 Linux 的自動執行程序 cron 來做這件事。
先將執行的指令寫成腳本,打開 GCP 的 VM,輸入
mkdir cronscript && cd cronscript
vi update_fb_group.sh內容是
tweeper https://www.facebook.com/groups/cloudnative.tw > ~/rssfeed/cloudnative.tw.xml
然後要讓 VM 能依照排程,自動執行這支腳本,因此需要使用 cron
crontab -e打開 crontab 後有範例,依照設定定期執行的時間後,就會定期執行預設的腳本
# m h dom mon dow command
0 */1 * * * /home/ken/cronscript/update_fb_group.sh第一行的 0 表示 0 分時執行,第二行的 */1 表示每小時執行,最後的 command 表示需要執行的指令。
如此一來,服務架設完成,我們有正式的 RSS feeds 了。
小結
讓我們來看看 feedly 抓資料的速度

該筆資料在 2019/12/07 14:58:24 發表,到 2019/12/08 11:17:51 時抓進 feedly,需要快一天,呃,好慢。因為我們的 cron 是每小時更新,速度慢純粹是 feedly 的問題了,依照 feedly 官方的說法,fetcher 是一小時左右抓取一次,可能它有自己的演算法,會再根據每個 feed 的活躍度修改抓取頻率?
且不管速度,至少這樣一來,我們能方便管理訊息了。我統計過,自己一天在 FB 的訊息量大約是 20+,有 feedly 能協助管理訊息後,Facebook 終於可以回歸到乾淨的版面了。