掌握 Redmine 的活動指標:繪製熱度圖
我們平常使用 Redmine 來管理專案,當需要進行 Review 或討論如何改善時,常常需要基於 Redmine 的數據。由這些數據分析,也能得知團隊執行狀況是否順利。但是 Redmine 本身並沒有整合 Dashboard 的功能,因此需要透過 RESTful API 來取得專案資料,再使用第三方軟體繪製成圖表。
安裝 python-redmine
由於 Python 是我熟悉的腳本語言,選擇用 Python 來進行 Proof of Concept,首先安裝相關的 Python 套件
python -m pip install python-redmine如果電腦有支援 pip 指令,可以直接用
pip3 install python-redmine來安裝。
Windows 的 pip 使用可能跟 Ubuntu 不同,至少我還沒找到用法,這邊選擇用 option-m 的模組執行方式,來執行 python 內的 pip module,效果跟 pip 相同,只是命令比較不直覺。
登入 redmine
python-redmine 已經將 redmine 的 API 指令封裝成 python 的語法,直接調用即可,我們先使用帳號密碼登入 redmine
from redminelib import Redmine
redmine = Redmine('http://demo.redmine.org', username='foo', password='bar')第一個參數填入 redmine 所在的 url,後面帶自己的帳號與密碼,如果無法登入,可以參考官網說明,請管理員將 REST API 打開。
取得 issue 列表
我的目標是取得 redmine 上的所有 issue。其中包含 assign 給我的 issue 量、我已經處理完成的 issue 量,藉此來觀察專案的成果。
首先是 assign 給我的數量
issues = redmine.issue.filter(
project_id='demo',
status_id='*',
assigned_to_id=me
)
print("Total opened count is: " + str(issues.total_count))filter 可以設定要取回的 issues 條件;我要取回的是在 demo 專案下、任意狀態、assign 給我的 issues。
同樣的,我們也可以取得我已經完成的 issue
issues_closed = redmine.issue.filter(
project_id='demo',
status_id='closed',
assigned_to_id='me'
)
print("Total closed count is: " + str(issues_closed.total_count))畫出 Heatmap
接著,我希望可以將平常在 redmine 上的活動畫成 heatmap,畢竟對專案而言,活躍度是非常重要的指標,而活躍度的指標之一就是更新頻率。遍歷所有的 issue,查詢底下的 journal 是否是由我發出,如果是的話,在 heatmap data array 的對應欄位 +1,藉此統計活動狀況。
import re
import datetime
import numpy
week_start = int(datetime.date(2019, 3, 3).strftime("%V"))
week_end = int(datetime.date(2019, 8, 31).strftime("%V"))
week_duration = week_end - week_start + 1
journal_ken = 0
data_arr = numpy.zeros((7, week_duration))
p = re.compile("(\d{4})-(\d{2})-(\d{2})")
for issue in issues:
for resource in issue.journals._resources:
if not resource['user']['name'] == "Ken Chen": continue
match = p.match(resource['created_on'])
if not int(match.group(1)) == 2019: continue
journal_ken += 1
week = int(datetime.date(2019, int(match.group(2)), int(match.group(3))).strftime("%V"))
weekday = int(datetime.date(2019, int(match.group(2)), int(match.group(3))).strftime("%w"))
data_arr[weekday][week - week_start] += 1
print("Total journal of Ken is: " + str(journal_ken))week_start 、 week_end 、 week_duration 用來限制時間範圍,使用正則表達式來判斷 journal 的時間是否落在指定的區段, journal_ken 用來統計總數。
得到資料陣列後,就能使用 seaborn 畫成圖
import seaborn as sns; sns.set()
import matplotlib.pyplot as plt
ax = sns.heatmap(
data_arr
)
plt.show()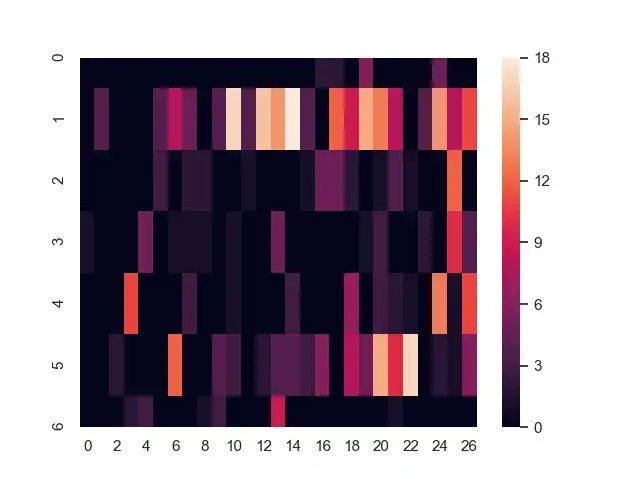
修飾 Heatmap
預設圖片跟想要呈現的效果有段落差,如果直接拿出去,大概會立刻被打槍,這邊需要進行一些美化,使用 seaborn 的參數來調整
data_masks = numpy.zeros((7, week_duration))
for i in range(7):
for j in range(week_duration):
if data_arr[i][j] == 0: data_masks[i][j] = 1
ax = sns.heatmap(
data_arr,
cmap = 'Blues',
mask=data_masks,
yticklabels = ["Sun","Mon","Tue","Wed","Thu","Fri","Sat"],
linewidths = 1,
square = True,
cbar = False
)
ax.set_ylim(0,7)
plt.show()修改顏色;加入遮罩遮掉值是 0 的區段;加入 y 軸標示;加粗格線;讓顯示的區塊為方形;拿掉色彩條。 ax.set_ylim 則是因為 matplotlib 本身的 Bug 會導致圖片只畫一半
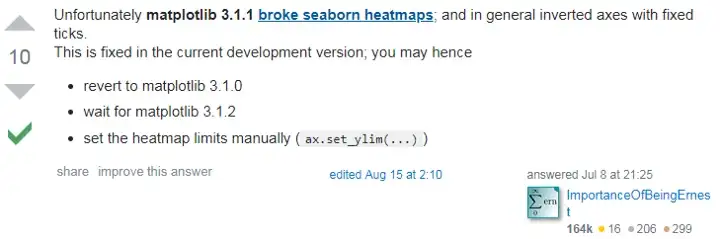
如果不想用開發中的版本,要不就等 3.1.2 版,要不就退回 3.1.0 版,要不就使用 ax.set_ylim 。我不太想動版本,只好乖乖使用指令來調整。
當一切就緒後,我們就可以得到
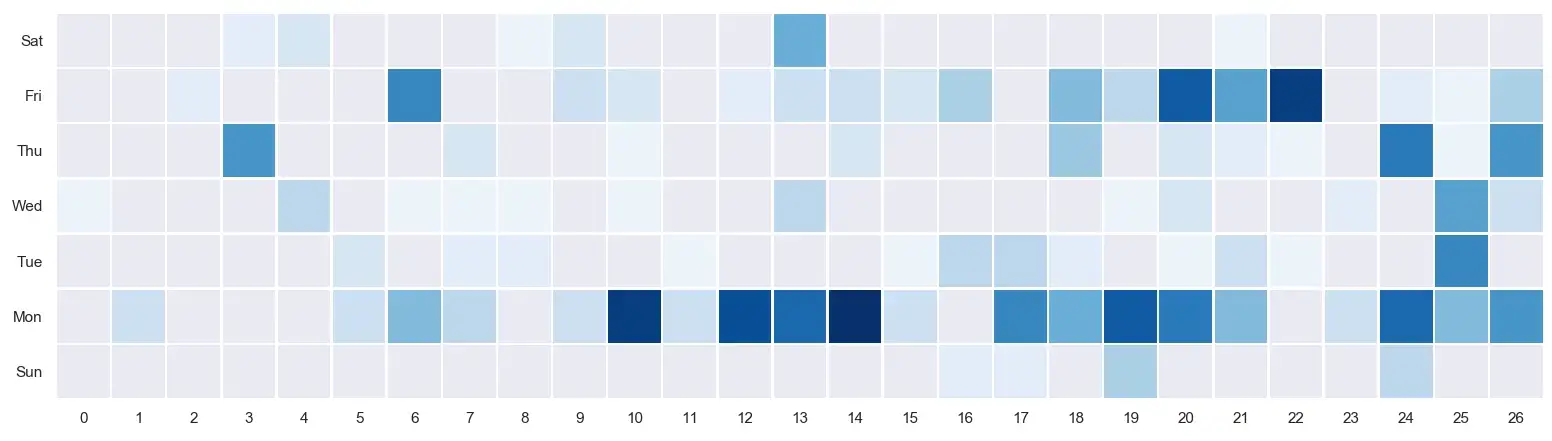
小結
稍微用 python 開個小小的 side project,就能體會到用 python 來驗證概念的威力。由於有完整的生態系,python 適合快速開發,快速驗證,很快就能知道自己的想法是否行得通,不用花費一堆時間蓋完基礎建設後,才發現由於需要的 API 沒開出來,導致專案 Fail。
資料視覺化真的是很有意思的題目,如果有機會的話,很想將整個團隊的資料即時視覺處理,跑專案時只要進到戰情室就能一目了然。
最後,我對 python 不支援 var++ 的用法有點意見,對 C 語言的工程師來講不太友善。