關於消息的三層語義:以 RabbitMQ 為例

對分散式系統來說,消息的可靠性非常重要,想想一個金融應用的場景,如果在支付時,消息遺失了,或是重複遞送了,都會造成使用者的困擾。當我們在系統中引入消息隊列時,我們同時引入了複雜度,這意思是,系統的「處理消息」跟你想的不一定是同一件事。從可靠性的角度來看,「處理消息」的語義可以分為三個層次,第一層是「最多一次」,當你請系統處理消息時,它會幫你進行,但最多一次,並且不保證是否完成;第二層是「最少一次」,系統會幫你處理消息,而且附帶必要的錯誤處理,確保消息至少被完成一次;第三層是「準確一次」,意指消息不多不少,恰恰好被準確處理並完成了一次。
當試著從語言學的角度來看待系統時,我們才能規劃出系統的整體面貌。儘管「準確處理一次」有最佳的可靠性,但因為其處理成本,降低了系統整體的吞吐量。在〈Starbucks Does Not Use Two-Phase Commit〉一文中,Gregor Hohpe 精確描繪了星巴克的異步系統。收銀員收費後,將咖啡杯放到隊列中,等待咖啡師處理,再交給取貨區的顧客。這個過程中,收銀員跟咖啡師不會特別確認咖啡杯的狀態,假設咖啡杯被放錯位置,直到顧客反應前都沒有人會知道,這是「最多一次」的語義;但如果咖啡杯掉落到地上,他們可能會重新做一杯新的咖啡,這裡就是「最少一次」的語義。因此我們可以說,星巴克是在「最多一次」的基礎上,有部分操作實現「最少一次」的語義。
AMQP & RabbitMQ
軟體的隊列設計也需要面臨類似問題,讓我們來看看 AMQP 的例子。AMQP 是由 JP Morgan Chase 提出的通訊協定,目的是為了讓消息隊列有個開放式的標準可以依循,如此一來,不同的語言跟架構能夠建置共通的應用程式。在 2007 年,Rabbit 公司開發一套開源軟體來實作 AMQP,稱為 RabbitMQ,現在由 Pivotal 維護。也因為它開源加上支持多語言客戶端,許多消息隊列會採用 RabbitMQ 來執行。
AMQP 的訊框格式是
+ — — — + — — — — -+ — — — — -+ + — — — — — — -+ + — — — — — -+
| type | channel | size | | payload | | frame-end |
+ — — — + — — — — -+ — — — — -+ + — — — — — — -+ + — — — — — -+
訊框的類型(type)分為 4 種。應用上常碰到的有 3 種
- METHOD(1):該訊框用於傳送 AMQP 的指令
- HEADER(2):該訊框用於傳送 AMQP 的標頭
- BODY(3):該訊框用於傳送 AMQP 的內容
其中 METHOD 會依照命令的不同,而有不同的參數(Argument),實現越進階的語義就需要仰賴越複雜的設定。
At most once
先從最基本的「最多一次」來看。最多一次可以指生產端,也可以指消費端。對生產端來說,只要發佈一次消息就算完成語義,後續也不會再重發。這裡我們使用開源庫 go-rabbitmq,來當 Golang 的 RabbitMQ 的客戶端,程式碼會是
producer.Publish(
[]byte(“hello”),
routingKeys,
rabbitmq.WithPublishOptionsExchange(exchangeName),
)指定好內文、路由規則、還有交換器,進行發送。
因為已經保證了傳遞「最多一次」,消費端只要在這基礎上進行消費,就能達成語義
consumer.StartConsuming(
consumeMessage,
queueName,
routingKeys,
)
func consumeMessage(d rabbitmq.Delivery) rabbitmq.Action {
fmt.Println(string(d.Body))
return rabbitmq.Ack
}指定消費函數、隊列名稱、路由規則來消費。
用 WireShark 抓封包的話,會看到 Basic.Publish 發佈了一次的消息
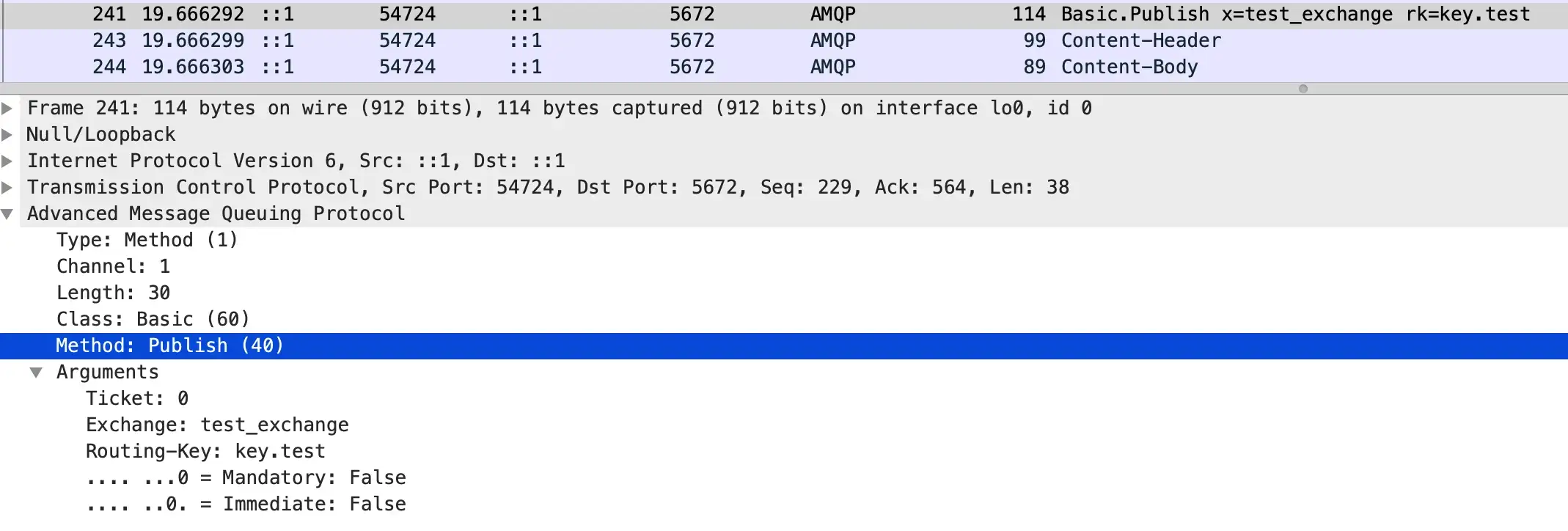
消費端也用 Basic.Consume 進行了消費
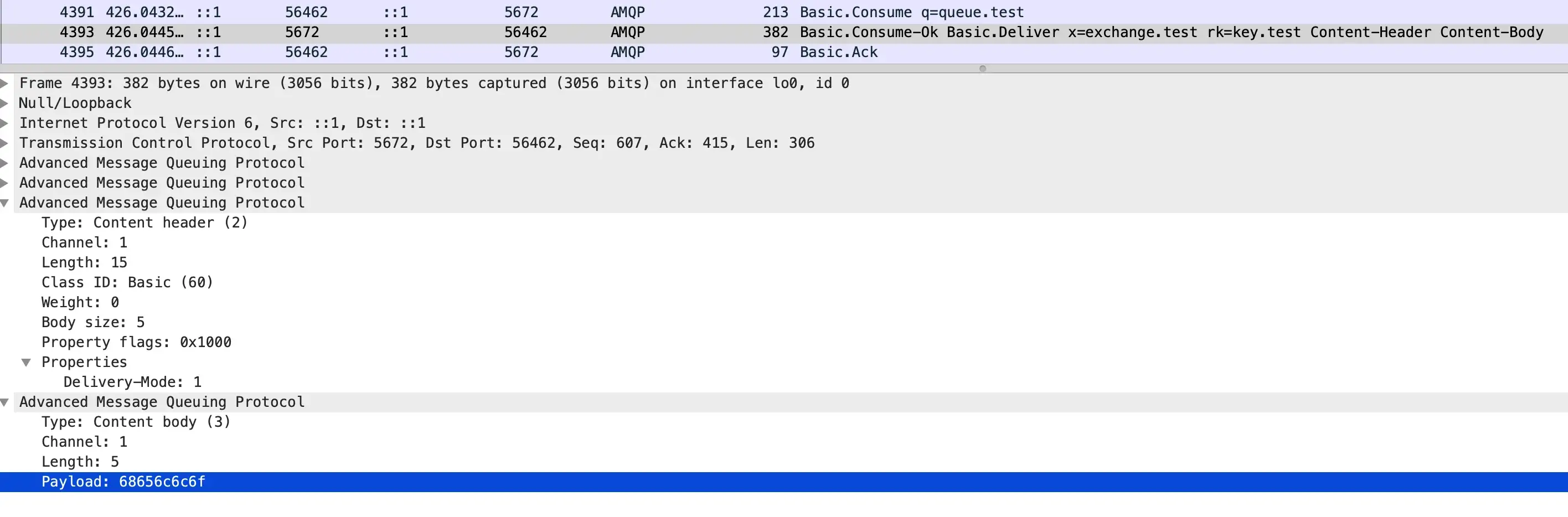
At least once
「最多一次」對於分散式系統的應用來說是遠遠不夠的,假設客戶購買商品,產生一則消息,這個消息卻在傳遞的過程中因為一些網路問題而讓消息丟失,像是某人突然拔掉網路線,或是供電的電廠跳電,如果使用「最多一次」的語義,直到客戶反應前,我們都不會知道這個問題,同時,因為消息傳遞到一半丟失,有可能會造成系統狀態不一致,有部分系統已經執行過消息,有部分系統則是沒有。
如果問題是由消息丟失引起的,最直覺的想法就是重試。想想,客戶向星巴克的店員抱怨,他點的咖啡還沒好,店員查詢後發現漏單,因此重做一份,這稱為重試(Retry)。
同樣先從生產端來看。要重試,就需要先知道原本的消息是有否正確傳遞。這裡可以用 AMQP 的 Confirm 機制 來實現,時序圖上是
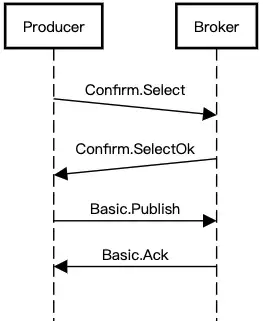
在建立 channel 時,聲明這個 channel 需要 confirm。Broker 收到後會回 Confirm.Select-Ok,表示同意生產者將 channel 設為 confirm。之後,每次生產者發佈消息後,都會收到 Ack,如果因為 RabbitMQ 自身的問題導致消息丟失,則會回傳 Nack 給生產者。
程式碼會是
comfirmCh := producer.NotifyPublish()
producer.Publish(
[]byte(“hello”),
routingKeys,
rabbitmq.WithPublishOptionsExchange(exchangeName),
rabbitmq.WithPublishOptionsMandatory,
rabbitmq.WithPublishOptionsPersistentDelivery,
)
comfirmation := <-comfirmCh
fmt.Printf(“receive: %+v\n”, comfirmation)遺憾的是,僅僅這樣還不算達到「至少一次」的語義。讓我們更進一步思考情境。假設 Broker 能收到消息,可是卻因為設定的因素,導致消息無法被放入隊列,例如使用了一組不存在的路由規則。那 AMQP 應該如何通知這類「運行正常但邏輯有誤」的情況呢?這時需要用到 mandatory 這個 Publish 的參數。
當 Publish 附帶 mandatory 時,生產端會告訴 Broker,這則消息需要被放進 Queue 中,如果沒辦法放入的話,需要將此消息退回給我。在程式碼上,需要改成
comfirmCh := producer.NotifyPublish()
returnCh := producer.NotifyReturn()
err = producer.Publish(
[]byte("hello"),
[]string{"non-existence"},
rabbitmq.WithPublishOptionsExchange(exchangeName),
rabbitmq.WithPublishOptionsMandatory,
)
comfirmation = <-comfirmCh
fmt.Printf("receive: %+v\n", comfirmation)
returnVal := <-returnCh
fmt.Printf("receive: %+v\n", returnVal)
if err != nil {
fmt.Println(err)
}到此,我們可以確保消息會被放進隊列,但我們仍然沒辦法確保這則消息被放進隊列後,Broker 會突然關閉,導致消息丟失。要防範這情況,就需要持久化隊列中的消息。RabbitMQ 的持久化分爲三個部分:交換器的持久化、隊列的持久化和消息的持久化。這裡會需要操作的是後兩者。如果只設置隊列持久化,重啓 RabbitMQ 後,消息會丟失;只設置消息的持久化,重啓之後隊列消失,繼而消息也丟失。因此隊列跟消息的持久化都需要設定。
要設定隊列的持久化,用
conn, err := amqp.Dial(cfg.Url)
ch, err := conn.Channel()
// the second arg is durable
_, err = ch.QueueDeclare(name, true, false, false, false, nil)同時,在發布的消息中設定消息持久化
err = producer.Publish(
[]byte("hello"),
routingKeys,
rabbitmq.WithPublishOptionsExchange(exchangeName),
rabbitmq.WithPublishOptionsMandatory,
rabbitmq.WithPublishOptionsPersistentDelivery,
)來看 WireShark 抓到的封包
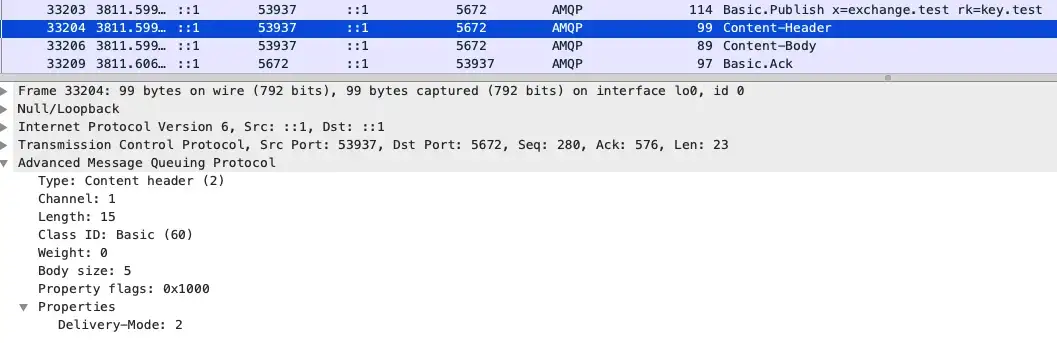
可以看到 Header 的 Delivery-Mode 被設為 2,指的就是有持久化消息。
在傳遞「最少一次」的基礎上,消費端要保證消息也至少被消費一次。這個相對單純,只需要消費完成後,用 Ack 回應 Broker 消費已完成。如果 Broker 沒收到 Ack 且連結斷開,那再下次建立連結時,Broker 會重新發送消息。
Exactly once
「最少一次」的問題很明顯,要是消息不斷被重複發送,有可能導致同樣的消息被重複處理,以電商的情境為例,有可能出現重複扣款的狀況。對於重複不敏感的場景,例如物聯網資訊蒐集,「最少一次」已經足以應付,但對金融場景來講,重複扣款是個嚴重的問題。
為了達到「準確一次」的語義,會需要在「最少一次」的基礎上,加上去重複的機制。最直覺的想法是替所有消息都加上 ID,當收到消息時,會將該 ID 緩存起來,日後如果收到新的消息,先確認緩存中沒有重複的 ID 再進行處理。這個技巧又稱為「冪等鍵」,意思是將操作冪等化,不論重複送多少次,都會得到相同的結果。
RabbitMQ 沒有實作緩存確認的機制,因此無法保證「準確一次」。這可以分兩個方向來看,假設生產端正在等待 Broker 回覆 Confirm,此時網路斷開,生產端偵測到異常,為了滿足「至少一次」,生產端重複發送消息,RabbitMQ 的 Broker 中就會存在兩條相同的消息。或者,消費端在消費完消息後,因為網路斷開,Broker 沒收到 Ack,則在連線恢復後,Broker 會將同樣的消息再度發送給消費端,造成重複消費。
如上面講到的,因為 RabbitMQ 沒有辦法保證每個步驟能「準確一次」,我們得退而求其次,希望能做到端到端的「準確一次」。這代表說,我們不在意 RabbitMQ 中間是否存在重複遞送,只要訊息最後能被準確消費一次即可。
要達成這件事,生產端需要替每則訊息加上 unique ID
err = producer.Publish(
[]byte("hello"),
routingKeys,
rabbitmq.WithPublishOptionsMessageID(uniqueID),
rabbitmq.WithPublishOptionsExchange(exchangeName),
rabbitmq.WithPublishOptionsMandatory,
rabbitmq.WithPublishOptionsPersistentDelivery,
)消費端收到訊息後,確認緩存內沒有 uniqueID,再進行處理
func consumeMessage(d rabbitmq.Delivery) rabbitmq.Action {
if cache.IsExist(d.MessageId) {
fmt.Println("duplicated message")
return rabbitmq.Ack
}
cache.Store(d.MessageId)
fmt.Println(string(d.Body))
return rabbitmq.Ack
}用 WireShark 也能看到 MessageID
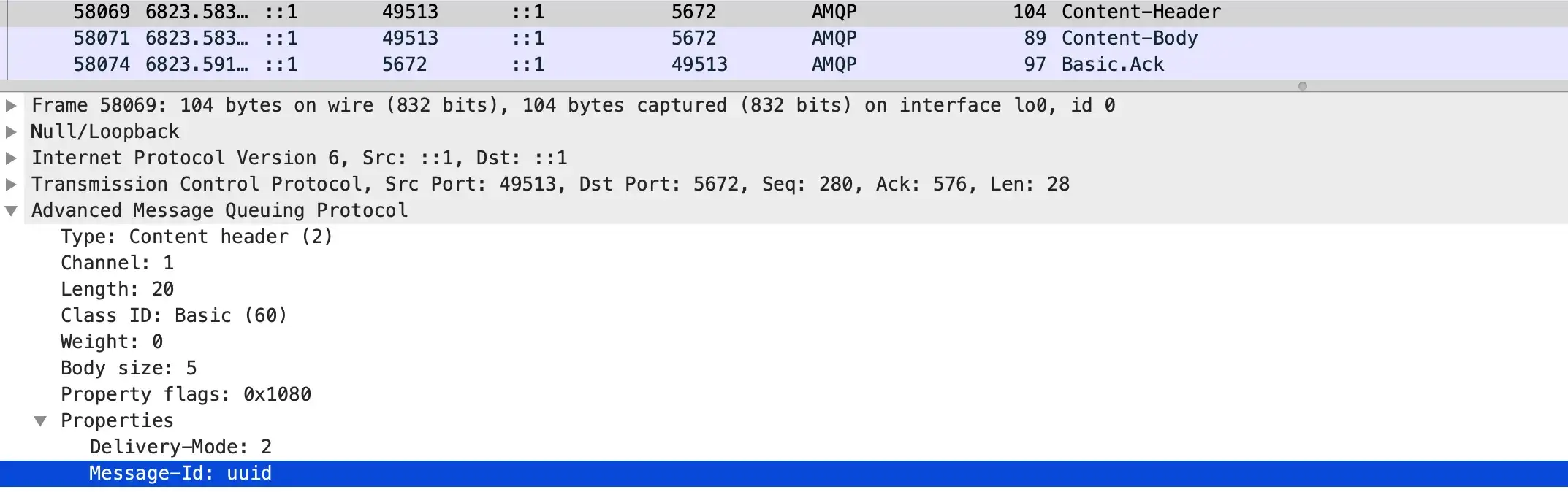
因為我們是在業務層面保證「準確一次」,實作方式就會跟系統相關,像是引入集中式緩存(Redis)會增加系統複雜度;而緩存的空間與失效期間也需要設計,這就不是單單調整參數就好,而是需要視具體運作的狀況來確定了。
小結
軟體工程的其中一項挑戰來自於「語義鴻溝」,可以看到光是消息處理就存在著三層不同的語義,而且越高階語義就需要越複雜的設定。如果消息處理跟使用者的期待有落差,很容易產生無形的錯誤。可能對於大多數的使用者來說,都是以「準確一次」為預設,開發者也不會跟使用者講,消息丟失算是正常情況(即使在有條件的情況下,它的確是正常)。
也許可以這麼想:身為開發者,如何盡早辨識出語義鴻溝,並提出對應的技術方案,就是功力所在了。雖然用層次的概念來描述語義,好像會給人只要實作高層次就好的印象,但高層次的保證需要更多操作,像是更多的 Confirm、跟緩存間更多的溝通,都會影響到其他效能指標。以「準確一次」來說,還得確保緩存不會在執行中出問題,如果有問題的話,錯誤處理也要額外設計。
商業模型跟技術模型間如何對應一直是很有意思的題目,希望大家看完這篇後能體會到消息處理有趣的地方。