OpenTelemetry 的可觀察性工程:以 Sentry 為例

點進 OpenTelemetry 的官方文件,它最先映入眼中的句子是「什麼是 OpenTelemetry」。例如,它是套可觀察性框架,用於檢測、蒐集與導出遙測數據;它是開源且供應商中立,能搭配其他的開源工具,像 Jaeger 或 Prometheus;它能將應用程式與系統儀表化,無關是用 Go 還是 .NET 開發,也無關部署在 AWS 還是 GCP 上。
但是身為一名開發者,當下我們想的是:「公司常開發一些沒人要用的功能,聽說 OpenTelemetry 可以提高可觀察性,也許我們應該放棄開發功能,轉頭建立更好的開發環境。」「AWS 常常要不到需要的數據,也許我們應該改用另一套工具,像是 OpenTelemetry,來解決這件事。」我們想像 OpenTelemetry 「應該」要能解決目前面臨到的一些問題,就像在技術的鏡像中尋找願望一樣。
如果已經有在用 Sentry,還需要導入 OpenTelemetry 嗎?我是不是應該讓技術更「標準」一點?某次與朋友交換意見後,我腦中突然浮現這個疑問。
訊號的複雜度
OpenTelemetry 將訊號描述為
Signals are system outputs that describe the underlying activity of the operating system and applications running on a platform. A signal can be something you want to measure at a specific point in time, like temperature or memory usage, or an event that goes through the components of your distributed system that you’d like to trace.
訊號是描述作業系統及平台上執行的應用程式底層活動的系統輸出。訊號可以是你想在特定時間點測量的項目,例如溫度或記憶體使用量,或是你想追蹤的分散式系統中經過各個元件的事件。
簡單來說,訊號是那些你會想收集的資料。
哪些資料?在 2018 年 12 月於美國西雅圖舉行的 KubeCon 北美大會上,Ben Sigelman 發表了「三大支柱,零答案:我們需要重新思考可觀察性」的演講 ,指標 / 日誌 / 追蹤被稱為可觀察性的三大支柱;而 2019 年的 KubeCon + CloudNativeCon EU 大會,Grafana 的 Tom Wilkie 與 Redhat 的 Frederic Branczyk 進一步指出,僅僅只是蒐集指標 / 日誌 / 追蹤,不代表你解決了可觀察性的問題。例如,指標可能告訴你應用程式的記憶體過高,迫使程式關閉,但你不會知道是哪一行程式碼導致記憶體洩漏。
隨著時間過去,軟體模型變得更加複雜,訊號只會越來越多。如果你需要熟悉所有訊號才能實施可觀察性,那這一天永遠不會到來。CNCF 顯然意識到這問題,他們試著自問:有沒有一種通用的訊號類型,能讓可觀察性的實施更單純一些?結論是沒有,他們解釋
In the same way, we can't have a single bicycle that works efficiently on both asphalt roads and off-roads. Each type of signal is highly specialized for its purpose.
就像我們無法擁有一輛既能高效在柏油路上騎行又能適用於越野的單車一樣。每種類型的信號都是為其特定目的高度專門化的。
高度專門化的意思是,你需要為不同訊號制定不同的技術方案。像是日誌,通常需要一字不漏存放在資料庫,當需要查詢時,最好能立刻鎖定對應的關鍵字;至於追蹤,在意的是特別慢的案例,只要取樣具有代表性,能不能完整保存並不重要。這些實務因素使得訊號儲存在不同地點,有不同的資料模型,缺乏一條明確的線索將它們串聯起來。
而線索是重要的,有效的可觀察性必須面對業務問題。舉例來說,當 501 錯誤請求激增,我們需要用日誌來了解具體的錯誤訊息,如果錯誤來自多個跳轉背後的內部微服務,我們需要使用追蹤 ID 來導航,好知道是哪個服務 / 流程該負責。CNCF 提出一套關聯模式,藉由時間區間(time range)、詮釋資料(metadata)與取樣範例(exemplar),我們可以把訊號串聯起來,從而建立起有效的可觀察性。
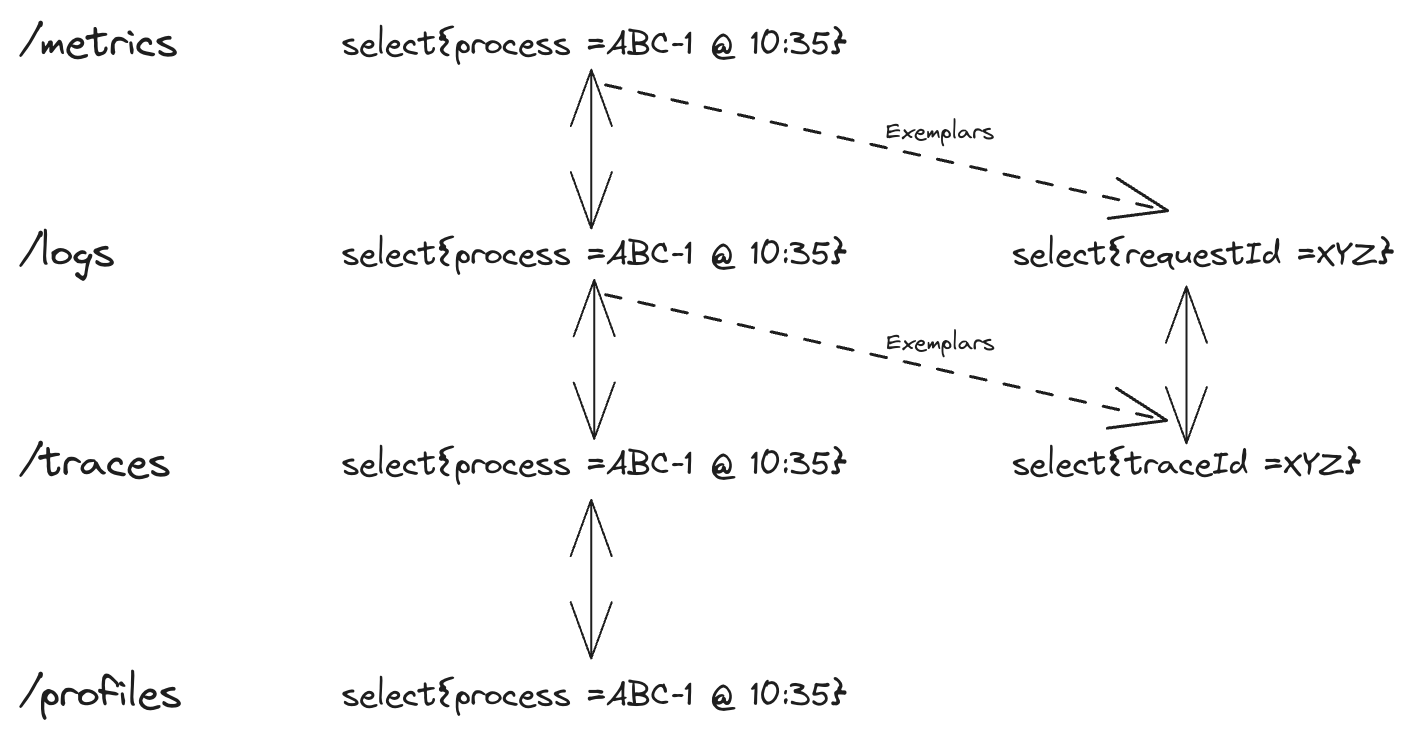
上下文傳播
通向有效可觀察性的道路存在許多障礙,如同前面討論的,訊號存放在不同的基礎設施中,只有當這些基礎設施都說著同一套語言,它們才可能彼此關聯。在最最簡單的情況中,某一家可觀察性軟體領導了市場,它熟悉所有的產業應用,知道該如何收集 / 匯出 / 儲存資料,而且不斷做出正確的決定,那我們也許可以期待它串聯內部訊號--顯然這並不現實。另一個情況是,由具可觀察性經驗的從業人員組成專案小組,探討如何汲取經驗,找出一條人人可前進的方向,這個方向日後成為了 OpenTelemetry。
OpenTelemetry 將實現訊號關聯性的方式稱為「上下文傳播」
With context propagation, signals can be correlated with each other, regardless of where they are generated. Although not limited to tracing, context propagation allows traces to build causal information about a system across services that are arbitrarily distributed across process and network boundaries.
透過上下文傳播,訊號可以彼此關聯,無論它們產生於何處。雖然不限於追蹤,上下文傳播允許追蹤在跨越任意分布於程序和網路邊界的服務中,建立系統的因果資訊。
在預設中,它使用 W3C 規範的 TraceContext 跟 Baggage 來記錄追蹤 ID 跟應用程式詮釋資料(metadata)。TraceContext 被分成兩個獨立的傳播欄位,traceparent 標頭代表追蹤系統中的請求,而 tracestate 標頭設計為供應商專用,讓供應商得以進行擴充。這是個 TraceContext 的範例
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
tracestate: congo=t61rcWkgMzE而 Baggage 以鍵值對表達應用程式的資訊,它的範例是
baggage: userId=alice,serverNode=DF%2028,isProduction=false
透過 TraceContext 跟 Baggage,可觀測性解決了分散式追蹤上下文的問題,但它們不是 OpenTelemetry 限定。任何可觀察性工具,都可以用類似的邏輯,來設計自己的上下文傳播方式,例如 Sentry
What happens in the background is that Sentry uses reads and further propagates two HTTP headers between your applications: sentry-trace, baggage
背後發生的事情是,Sentry 會讀取並在您的應用程式之間進一步傳遞兩個 HTTP 標頭:sentry-trace, baggage
直接打開 Sentry 的官網,可以看到它們是如何追蹤訪客訊息
baggage: sentry-environment=vercel-production, \
sentry-release=e4f219dbd5f349299b7e556ff2eb494d8585e7be, \
sentry-public_key=ad63ba38287245f2803dc220be959636, \
sentry-trace_id=e921cc4ea33f4843a997c56af332a807, \
sentry-sampled=true, \
sentry-sample_rand=0.1425299860922582, \
sentry-sample_rate=1
sentry-trace: e921cc4ea33f4843a997c56af332a807-a0d220006b97eea9-1可觀察性時代的監控軟體
Sentry 是一款應用監控軟體(Application monitoring software),這在 2025 年聽起有點老派。Honeycomb 的 CTO Charity(可觀察性 2.0 的用語發明人)曾半開玩笑說
Technically, we started out by defining observability as differentiated from monitoring, but the market has decided that everything is observability, so … we need to find new language, again. 😉
技術上,我們一開始是將可觀察性定義為與監控不同,但市場已經決定一切都是可觀察性,所以……我們又得找新的語言了。😉
我喜歡 Charity 文章中對技術的直覺,儘管有時顯得過於奔放(可觀察性 2.0 純粹是開玩笑,而焦慮的技術行銷人員則兩眼發光接受它)。在另一篇討論監控的文章中,她解釋傳統監控工具的運作方式
Monitoring involves gathering metrics and evaluating specific facets of a software system’s efficiency against predetermined thresholds. The primary objective is to issue alerts and notifications when known conditions are met, typically because they could signal that issues might be happening. Monitoring can help engineers pinpoint performance issues, presuming they know which exact conditions to look for.
監控涉及收集指標並根據預先設定的閾值評估軟體系統效率的特定面向。主要目標是在已知條件達成時發出警報和通知,通常是因為這些條件可能表示問題正在發生。監控可以幫助工程師定位效能問題,前提是他們知道要尋找哪些具體條件。
舉個例子,你知道硬碟只有 1TB 的空間,因此你設置了警報,當硬碟空間達到 900GB 時,系統會自動通知你清除用不到的檔案,這是傳統的監控工具。而在雲端時代,系統變得過於複雜,只依賴監控幾乎不可能達到服務級別目標(SLO),想想 Slack 中突然跳出 20 個警告,你知道原因是什麼嗎?如果現代監控軟體只能監控而不能知道系統如何運作--也就是不具備可觀察性的話,只能等著被淘汰。
在這意義上,Sentry 必須具備可觀察性,這是基本條件。Sentry 值得討論的地方在於,它認為自己提供的不只是可觀察性,還有可除錯性
Sentry is the first debuggability platform, offering a connected debugging experience across traces, metrics, and other key pieces of data. The tools that makeup Application Performance Monitoring, like error monitoring, performance monitoring, session replay, code coverage, and crons monitoring, contribute to a system’s overall observability. Having a system with good monitoring and observability is the start, as ultimately, developers need data that is actionable. And that’s where debuggability comes in. Debuggability is the contextualization and actionability of a solution. Simply put, debuggability exists to help developers know how to fix issues, and making data actionable is what Sentry is all about.
Sentry 是首個可除錯性平台,提供跨追蹤、指標及其他關鍵數據的連結除錯體驗。構成應用程式效能監控的工具,如錯誤監控、效能監控、會話重播、程式碼覆蓋率及排程監控,皆有助於系統的整體可觀察性。擁有良好監控與可觀察性的系統是起點,因為最終開發者需要的是可行動的數據。而這正是可除錯性的意義所在。可除錯性是解決方案的情境化與可行動性。簡單來說,可除錯性存在的目的是幫助開發者知道如何修復問題,而讓數據可行動正是 Sentry 的核心。
Sentry 的議題(Issue)是一組相似事件的集合,這些事件通常是錯誤,但也有可能是開發者關心的資訊。發生的議題將集中到「工作籃」,驅使開發者經常回訪並清理。在處理的過程中,開發者會需要更多的資訊,像是議題發生的時間與地點,相關的上下文,具體的程式碼行,才能知道問題發生的根本原因。Sentry 將這些資訊串聯在一起,例如,你可以在 Issues 頁面點擊 Trace ID,跳轉到 Traces 頁面查看分散式追蹤;或者在 Transaction 頁面查看 Profiles,以便確認特定操作是否導致效能問題。這與 CNCF 描述的關聯模式本質相同,只是 Sentry 用產品設計,將它打磨得更為直覺、更為流暢。
標準與應用的距離
拿 Sentry 跟 OpenTelemetry 對照,我們會發現它們的相似之處,例如,它們都會關聯訊號,從而建立更齊全的上下文。如果只看訊號,Sentry 僅有追蹤,沒有日誌跟指標,可是這不是問題,畢竟 Prometheus 也是以指標為主。既然 Sentry 已經具備一定程度的可觀察性,我們是否可以把它當成一種訊號後端,用 OpenTelemetry 送資料給它,好讓服務間的規格更一致?這是我一開始的提問:「如果已經有在用 Sentry,還需要導入 OpenTelemetry 嗎?」
只看程式碼層次,這有點像在問要選 Sentry 還是選 OpenTelemetry 的 SDK。如果希望依循標準又能保有 Sentry 的功能,你也可以使用 OpenTelemetry 的 SDK,再加上 Sentry 的函式庫來發送訊號給 Sentry。Sentry 有出一篇 OpenTelemetry Support 的說明,可以來看段偽代碼範例
func (p sentryPropagator) Inject(ctx context.Context, carrier propagation.TextMapCarrier) {
spanContext := trace.SpanContextFromContext(ctx)
sentrySpan, _ = sentrySpanMap.Get(spanContext.SpanID())
// Sentry span exists => generate "sentry-trace" from it
carrier.Set(sentry.SentryTraceHeader, sentrySpan.ToSentryTrace())
sentryBaggageStr = sentrySpan.GetTransaction().ToBaggage()
sentryBaggage, _ := baggage.Parse(sentryBaggageStr)
// Merge the baggage values
finalBaggage, _ := ctx.Value(baggageContextKey{}).(baggage.Baggage)
for _, member := range sentryBaggage.Members() {
var err error
finalBaggage, err = finalBaggage.SetMember(member)
if err != nil {
continue
}
}
carrier.Set(sentry.SentryBaggageHeader, finalBaggage.String())
}基本上是從 traceparent, tracestate 跟 baggage 中拿出資訊,然後放回 sentry-trace 跟 baggage 中。當然實際函式庫更為複雜,關係到語意上的轉換,例如 Sentry 的 Span 狀態碼是 17 個值的列舉,可以對應到 GRPC 跟 HTTP 的狀態碼,而 OpenTelemetry 的 Span 狀態碼是 3 個值的列舉,兩邊沒辦法對應,Sentry 的 Span Status 只能改放到 OpenTelemetry 的 Span Attribute 中。至於為什麼要特立獨行,Sentry 解釋它原本依照 OpenTelemetry 的規格來制定狀態碼,只是後來 OpenTelemetry 改規格了,呃……畢竟人家那時也還沒進 Stable。
依照 OpenTelemetry 的規格,「支援 OpenTelemetry」指供應商必須透過以下兩種機制之一接受預設 SDK 的輸出:
By providing an exporter for the OpenTelemetry Collector and / or the OpenTelemetry SDKs
透過提供 OpenTelemetry Collector 及/或 OpenTelemetry SDK 的匯出器
By building a receiver for the OpenTelemetry protocol
透過建置 OpenTelemetry 協定的接收器
只要讓 OpenTelemetry 可以送出你要的格式,或者你能接收 OpenTelemetry 標準格式,符合其中一種,我們就說該工具支援 OpenTelemetry。從這點來看,Sentry 支援 OpenTelemetry(或者嚴謹地說,在追蹤訊號上支援)。
然而這樣的支援沒有實質意義,讓我們想想,使用 Sentry 的目的是什麼?是為了快速識別並解決問題。如果只在追蹤使用 OpenTelemetry,而在議題事件仍然使用 Sentry 的 SDK,那麼就會出現一套應用,兩套監控的尷尬場面。此外,如果談的是端到端的可觀察性,也應該要納入瀏覽器應用程式(前端應用),頁面載入緩慢可能是瀏覽器效能的問題,也可能是客戶端網路環境不穩定。真實用戶監控(RUM)可以替產品帶來有效的商業價值--當你的使用者暴躁狂點頁面時,你會想知道原因--而這些都是 OpenTelemetry 目前尚未穩定的部分
OpenTelemetry JS has technically supported capturing spans from web browsers since its first releases, however this behavior was mostly unspecified, and there was no equivalent functionality for other types of client applications like those on Android, iOS, or Windows.
OpenTelemetry JS 自首次發行以來技術上已支援從網頁瀏覽器捕捉 span,但此行為大多未明確規範,且對於其他類型的客戶端應用程式(如 Android、iOS 或 Windows)則沒有相應的功能。
我能想到的一種場景是,維運團隊與開發團隊需要不同工具,維運團隊要掌握系統狀態,而開發團隊要快速解決問題。追蹤訊號可以使用 OpenTelemetry 來收集,而後發送給 Tempo 跟 Sentry,這樣一來,維運團隊可以看 Grafana,而開發團隊可以看 Sentry Issues。 這聽起來像什麼?是的,標準的康威定律。
有部分原因是現有的 OpenTelemetry 指標 / 日誌 / 追蹤無法覆蓋所有應用場景。Session Replay 可以展現使用者是如何操作網頁;Profiles 可以讓開發者理解系統的資源配置;Topology 則是顯示了資訊如何在網路上流動。這些都無法單純歸類到現有的訊號中。即使是在現有的訊號領域,仍然有許多語意約定等待定義,2024/11/04 發布的 CI/CD 管道屬性就是個例子。在 OpenTelemetry 覆蓋這些場景前,供應商只能參考草稿,或者依照自己的判斷來實作協定。
OpenTelemetry 的願景是「在不進行龐大且不可持續的工程努力的情況下,獲得高品質、隨插即用的遙測」,為了讓遙測無處不在,它最優先事項是持續改進 Collector 跟 SDK,使它們更容易使用,整合更多的儀表庫。這是一項基礎工程。而 Sentry 不一樣,它致力於「幫助每位開發者診斷、修復並優化他們程式碼的效能」,需要走在標準前面,Issue 跟 Transaction 都是 Sentry 獨有的概念,用於解決特定的情境問題,它也更關注開發者應用端的需求。
儘管 OpenTelemetry 有提供 SDK,它最大的意義還是供應商中立,如果你是基礎建設的供應商,例如 AWS 或 GCP,甚至資料庫的開發者,只要支援 OpenTelemetry,就能確保服務本身的可觀測性。如果你負責開發可觀測性後端,例如 Jaeger 或 Prometheus,因為有了 OpenTelemetry 的存在,你可以節省開發函式庫的成本,專注讓服務變得更好。Charity 說得對:「OTel 的重點是擺脫供應商鎖定,讓觀測性供應商透過優秀的服務來競爭你的業務,而不是因為無法擺脫而被迫使用。」
小結:道阻且長,行則將至
OpenTelemetry 的確像它宣稱的一樣,試圖成為雲端時代的開放標準,要達成這願景,它要做的事太多了。日誌是個好例子,OpenTelemetry 規格中說
Our approach with logs is somewhat different. For OpenTelemetry to be successful in logging space we need to support existing legacy of logs and logging libraries, while offering improvements and better integration with the rest of observability world where possible.
我們對日誌的做法則略有不同。為了讓 OpenTelemetry 在日誌領域取得成功,我們需要支持現有的日誌及日誌庫傳統,同時在可能的情況下提供改進和與其他可觀察性領域更好的整合。
這是一條漫長的道路,僅 Go 語言,OpenTelemetry 就支援 logr、logrus、slog、zap 等主流日誌庫,更別說還要支援其他語言,JavaScript、Java、.NET、C++ 等等。即使提供了 SDK,也還要開發者願意採用,為了降低認知負擔,OpenTelemetry 盡可能讓標準保持穩定一致,然而當涉及 API 時,仍需要開發者具備可觀察性的領域知識。
我可以想像,OpenTelemetry 有朝一日會成為基本配備,它讓系統更穩定,提高解決問題的速度,加速產品迭代,它訴說著一個訊號一致的前景。但以目前來說,它還有許多事情等待完成。訊號三本柱的說法,在提出一年後就有質疑的聲音出現。而最最重要的是,它仍然會遇到康威定律的限制,我們不應該把康威定律看成是部門組織的問題,根本上它關係到人認知世界的方式,要習慣開發的工程師去 K 可觀測性山一般高的名詞真的是不切實際……它甚至值得獨立成一門工程類型,就像前後端由軟體工程中拆分出來。
在 OpenTelemetry 的 Blog 也能看到類似說法
All interviewees agreed that there is a learning curve associated with OTel, especially when it comes to understanding the collector, configurations, and semantic conventions. Adriel noted that “it took me a lot of conceptual overhead to understand it.” Alexandre also mentioned that the documentation, while improving, could still benefit from more examples.
所有受訪者都同意,OTel 存在學習曲線,尤其是在理解收集器、配置和語義約定方面。Adriel 提到「我花了很多概念上的努力才理解它。」Alexandre 也提到,雖然文件正在改進,但仍然可以增加更多範例。
OpenTelemetry 航行在一條偉大的航道上,它透過開放社群的方式,達成一個共同且共享的理解,讓供應商能夠一起提供更好的價值。而供應商--例如 Sentry--在可觀察性上的探索,又反過來為 OpenTelemetry 帶來紮實的現場經驗。我得說它在實務現場仍有許多問題,但也正是在這個循環下,可觀察性的工程才能被慢慢建立起來。
Reference
- OpenTelemetry mission, vision, and values
- OTel Sucks (But Also Rocks!)
- Observability Whitepaper
- Three Pillars, Zero Answers: We Need to Rethink Observability
- Set Up Distributed Tracing
- Authors’ Cut—How Observability Differs from Traditional Monitoring
- Monitoring, Observability, & Debuggability Explained
- Another observability 3.0 appears on the horizon