OAuth 2.0:角色與信道

使用者體驗是 B2C 重要的產品面向。通常一個網路服務,會要求使用者註冊帳戶後才能開始使用——以台灣金融保險法規為例,使用者需要建立帳戶後,才能得到報價。站在行銷觀點,註冊會降低用戶的轉換率,因為它需要填寫姓名、暱稱、生日、信箱等資料,步驟相當繁瑣,對行動場景,這百分百是個負面體驗。這讓人不禁想問,這個環節是可以優化的嗎?
事實上,我們可以合理假設使用者資訊已經存在社群媒體中,例如 Google、Facebook、Twitter、GitHub,而我們需要的只是請求使用者同意,讓我們可以代表使用者,存取社群媒體中受限制的資源。也就是,我們關注的是有沒有一個授權框架,可以讓第三方應用取得對資源的訪問權限。
OAuth 2.0
這就帶到 OAuth 2.0 想要解決的問題。在傳統的 Client-Server 認證架構中,當客戶端要存取伺服端資源時,需要提供使用者的帳號密碼。如果發起請求的是第三方應用,則資源擁有者要將帳號密碼提供給第三方應用。可以想像,你需要請人幫你收信,就需要把家裡鑰匙交給對方。而這會有幾個問題:
- 第三方應用會儲存使用者帳號密碼,而且為了後續使用,會存成明文。
- 第三方應用會得到完整權限,使用者沒辦法限制第三方應用的使用時間與存取範圍。
- 第三方應用的存取權無法單方面撤回,如果修改密碼,不只是想撤回的應用,所有應用的存取權都會被撤銷。
- 任何第三方應用被駭,所有的用到該密碼的資源都可能被惡意人士存取。
角色定義
你可能會發現,我們要做的是件很衝突的事。一方面希望可以對應用授權,另一方面又希望授權不會有資安問題。處理過金融應用的人應該深有同感,金融的基礎就是信任,而信任關係著角色的分配與互動。以常見的例子來說,開發者跟維運人員的角色不同,不僅是為了讓責任更明確,也是為了防止開發問題影響到生產環境。
OAuth 2.0 在系統設計中,定義了四個角色
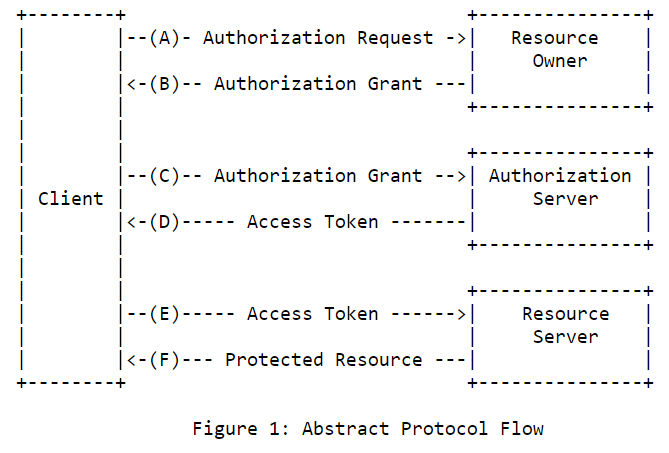
資源擁有者(Resource Owner) 是能授權訪問權限的主體。通常資源擁有者是終端使用者,他們握有密碼,能進行身分認證,並核可授權範圍。在網路世界,終端使用者會透過瀏覽器跟網路服務互動,我們可以把瀏覽器看成是使用者的代理人,稱為「用戶代理」,這意味著,安全的瀏覽器非常重要,一名不可靠的代理人容易有資安問題。
受保護資源(Protected Resource) 是資源擁有者存放在其他服務的資源,在社群媒體註冊的例子中,受保護資源是資源擁有者的個人資訊。如前面提到的,為降低服務的使用門檻,第三方應用希望取得既有的受保護資源,至於如何取得呢?第三方應用會在請求時攜帶 Token,說明自己有得到授權,受保護資源確認 Token 後,會允許第三方應用訪問核可的資源。
講到第三方應用,在 OAuth 2.0 的正式名稱叫客戶端(Client),是代表資源擁有者存取受保護資源的主體,可以理解成需要存取資源的應用。如前面講到的,該應用需要攜帶 Token 來請求資源。因此在 OAuth 2.0 中,它主要負責請求和使用 Token。
授權伺服器(Authorization Server) 負責認證與授權的伺服器。OAuth 2.0 為區別資源擁有者與客戶端兩個角色,在中間引入授權伺服器,將資源擁有者的權限轉換成客戶端使用的 Token。舉例來說,辦公室的門禁系統,員工可以持員工證進入大門,因為該員工證是系統發放的憑證。但使用同樣的憑證,卻可能進不去 SRE 的機房,因為機房不在該憑證的授權範圍內。藉由這樣的機制,限定受保護資源的存取,讓認證不等同授權。
Token
在前面的介紹中,我們說到客戶端跟受保護資源彼此隔離,透過授權服務器核發的 Token 來存取資源。因此在 OAuth 2.0 中,Token 代表著資源擁有者授予客戶端的存取權限。用門禁系統來比喻的話,可以看成是員工證這樣的工具。
值得注意的是,Token 對不同角色的透明程度不同,對客戶端來說,因為它不需要知道 Token 的內容,只需要在請求資源時攜帶 Token,所以 Token 對它是不透明的存在。這就像我們不需要知道員工證感應時傳遞了哪些資訊,只需要知道員工證可以打開大門。而授權伺服器負責頒發 Token,受保護資源負責驗證 Token,兩者都會需要知道 Token 具體的含意。在這裡,使用 Token,而不是帳號密碼的設計,可以讓客戶端保持單純,因為它不透明的特性,客戶端不會受到 Token 變動的影響。即使使用者的密碼更改了,客戶端仍然可以維持相同設定。
圍繞著 Token,也延伸出一個議題:權限應該如何獲取?我們可以想像,四個角色在處理授權時應該會遵循一套流程,OAuth 2.0 稱呼這套流程為授權許可(Authorization Grant),客戶端用它來取得 Token,並用 Token 向受保護資源發出請求。為因應不同的應用場景,RFC 6749 有定義出四套授權許可類型,分別是
- 授權碼許可類型(Authorization Code)
- 隱式許可類型(Implicit)
- 資源擁有者憑證許可類型(Resource Owner Password Credentials)
- 客戶端憑證許可類型(Client Credentials)
其中以授權碼許可類型最為普遍。
信道
現在我們有了角色,也有了流程。角色間要交流,就會需要有通信的管道,這稱為信道(Channel)。OAuth 2.0 是基於 HTTP 實現的,因此會使用 HTTP 來傳遞訊息,然而,HTTP 的通訊模型與 OAuth 2.0 的設計存在語義落差,我們需要找出彼此的對應關係,才能實現角色間的通訊。在這裡,我們依照通訊是否經過資源擁有者,將信道分為兩種類型:後端信道(Back-channel)與前端信道(Front-channel)。
後端信道(Back-channel) 使用常見的 Client-Server 通訊,因為通訊發生在資源擁有者的可見範圍外,所以稱為後端(Back)。具體來說,會依照授權許可的不同,而有不同的實現。像客戶端跟授權伺服器兌換 Token,或客戶端向受保護資源存取資源,都是通過後端信道。這樣的好處是,使用者不需要參與其中,動作能自動完成,而且因為請求沒有暴露,能降低攻擊面積,從資安的角度來講更加安全。
常見的後端信道請求類似
POST /token
Host: localhost:9001
Accept: application/json
Content-type: application/x-www-form-encoded
Authorization: Basic b2F1dGgtY2xpZW50LTE6b2F1dGgtY2xpZW50LXNlY3JldC0x
grant_type=authorization_code&redirect_uri=http%3A%2F%2Flocalhost%3A9000%2Fcallback&code=8V1pr0rJ而響應則是
HTTP 200 OK
Date: Fri, 31 Jul 2015 21:19:03 GMT
Content-type: application/json
{
"access_token": "987tghjkiu6trfghjuytrghj",
"token_type": "Bearer"
}前端信道(Front-channel) 是經過資源擁有者的通信管道,通過瀏覽器使用 HTTP 的重定向來實現。可能有人會好奇,既然已經有後端信道,而且資安防護上更好,為什麼還需要用前端信道來通訊?原因是,我們不希望由客戶端來進行身分認證與授權。資源擁有者可以把授權結果轉交給客戶端,可是不會把帳號密碼交給客戶端。它的目的是隔離客戶端跟授權伺服器間的通訊,讓資源擁有者參與到認證與授權過程,而不是由客戶端自行處理。
聽起來有些複雜,希望客戶端能得到授權結果,卻又不希望客戶端自行處理,這是什麼意思?當我們覺得軟體太複雜時,請想想身邊的例子。假設你現在想請假,會怎麼做呢?你會上請假系統申請假單,假單經主管簽核後生效,在請假日就可以不用上班。同樣的,當客戶端需要資源時,它會講說,請幫我到授權伺服器核准,核准後,授權結果才會轉交給客戶端。如果讓客戶端自行處理,就像一個員工可以自己簽假單,你會希望他簽核時有摸著良心。
在授權模型中,真正需要資源擁有者參與的,只有「認證」與「授權」,其他事情都希望能自動完成。前端信道的設計是利用 HTTP 的重定向跟瀏覽器收到重定向後的跳轉來達成。希望獲得授權的客戶端,會在瀏覽器發起請求時回覆
HTTP 302 Found
Location: http://localhost:9001/authorize?client_id=oauth-client-1&response_
type=code&state=843hi43824h42tj瀏覽器收到回覆後,因為有 302,會自動導向 Location 中的授權伺服器授權端點,交由資源擁有者與授權伺服器進行認證與授權。等到完成後,授權伺服器會回覆瀏覽器
HTTP 302 Found
Location: http://localhost:9000/oauth_callback?code=23ASKBWe4&state=843hi438瀏覽器收到後,會再重新導向到客戶端。
跟後端信道比起來,前端信道給了資源擁有者參與的空間,也給了惡意攻擊者攻擊的空間。就像前面討論的,前端信道是透過 HTTP 重定向的方式來傳遞訊息,而重定向是種間接的通訊方式,客戶端跟授權伺服器兩端,沒辦法知道發出的響應是否真的有到達目的地,也不知道中間是不是有被竄改跟複製。攻擊者可以攔截重定向的位置,修改後傳給受害者,而當受害者將修改後的重定向位置傳給授權伺服器時,授權伺服器也不知道這個請求的來源是正常還是惡意。因為這個緣故,在使用前端信道傳遞訊息時,會需要注意相對應的資安措施是否做到位。
小結
這篇文的出發點是想探討 OAuth 2.0 的授權模型。讓開發者在選擇授權許可時,能理解角色間的互動,還有設計上要注意的資安風險。資安問題也是 OAuth 2.0 這麼複雜的主因,實作上許多細節都是為了處理各種資安漏洞。要理解這些漏洞為什麼存在,就必須理解角色權責與信道,如果我是攻擊者,想取得 Token 好存取受保護資源,我可能會偽造角色(假的客戶端)或偽造信道(修改重定向後讓被害者使用),而這些偽造方式,又跟互動模式有密切關係。
希望讀完這篇文後,能幫助讀者釐清一些原本的困惑,知道 OAuth 2.0 的原理與限制。