標準化之路:Go 1.23 中的迭代器

Ian Lance Taylor 在 "Range Over Function Types" 這篇文章聊到 iterator 誕生的原因。如果我們有兩個容器,稱為集合(Set),想要取得這兩個集合中的不重複元素,加到新的集合中形成聯集,我們可以寫個 Union 函式來執行
// Set holds a set of elements.
type Set[E comparable] struct {
m map[E]struct{}
}
// Union returns the union of two sets.
func Union[E comparable](s1, s2 *Set[E]) *Set[E] {
r := New[E]()
// Note for/range over internal Set field m.
// We are looping over the maps in s1 and s2.
for v := range s1.m {
r.Add(v)
}
for v := range s2.m {
r.Add(v)
}
return r
}顯然,Union 函式要可以存取容器元素,換言之,容器(Set)的開發者需要設想使用者可能使用的「任何」情境,例如交集 / 互斥聯集 / 篩選,然後在函式庫中實現它們--這當然不現實。或者,開發者需要曝露容器元素,讓使用者自行存取。
不是所有開發者都願意曝露底層,從設計上來講也顯得多餘,明明使用者需要的只是迭代,沒道理要求開發者曝露結構。理想方案是,開發者能在隱藏容器元素的同時,也讓使用者進行操作。於是我們來到了一個問題:是不是有辦法將儲存資料的方式視為單純的容器,分離算法與結構?
用函式參數來分離
最簡單的方式,是讓容器的 method 支援迭代,而實際的動作由外面傳入。改寫 Taylor 的範例,變成
func (s *Set[E]) Visit(f func(E) bool) {
for v := range s.m {
if !f(v) {
return
}
}
}Visit 負責訪問元素,實際的操作則交給 f。在 Go 的標準庫中,sync.Map.Range 就是用這樣的方法實現
func (ht *HashTrieMap[K, V]) iter(i *indirect[K, V], yield func(key K, value V) bool) bool {
for j := range i.children {
n := i.children[j].Load()
if n == nil {
continue
}
if !n.isEntry {
if !ht.iter(n.indirect(), yield) {
return false
}
continue
}
e := n.entry()
for e != nil {
if !yield(e.key, e.value) {
return false
}
e = e.overflow.Load()
}
}
return true
}有個 for 迴圈會不斷取出元素,交給 yield 進行處理。
在 1.23 版以前,Go 的函式庫開發者需要自行設計類似的函式,不同人設計的函式會有不同的參數形式,多少會帶來一點混亂,例如,flag.Visit 的用法是
// Visit visits the flags in lexicographical order, calling fn for each.
// It visits only those flags that have been set.
func (f *FlagSet) Visit(fn func(*Flag)) {
for _, flag := range sortFlags(f.actual) {
fn(flag)
}
}與 sync.Map.Range 不同,flag 中不存在中止條件,因此它的函式參數 fn 不需要有回傳值。在 flag.Visit 中,每個元素都會被迭代到。
標準化的形式
我猜想形式上的分歧為生態系帶來一些困擾,這應該是 1.23 加入 iterator 的主要原因,Taylor 在文章中提到
We want to improve the Go ecosystem by developing standard approaches for looping over containers.
我們希望通過開發標準方法來遍歷容器,以改進 Go 生態系。
如果 iterator 是個常見的模式,與其讓開發者自行設計,不如從語言上原生支援。有意思的是,Go 團隊選擇擴展 for/range 的表達式,讓它能支援容器迭代的語意
As we all know, Go has container types that are built in to the language: slices, arrays, and maps. And it has a way to access the elements of those values without exposing the underlying representation: the for/range statement.
如我們所知,Go 語言內建了容器類型:切片、陣列和映射。它也有一種方法可以存取這些值的元素,而不暴露底層的表示方式:for/range 語句。
讓我們想想 map 等原生容器,這好像是個很自然的選擇,map 的使用者無需知道底層是 hash table,資料存放在一個一個的 bucket 中,他只要用 for/range 迭代 map 中的元素即可。當然,map 能有語法支援的原因,是因為它是原生容器,但要解決這問題也不難,只要擴展原本的 for/range 表達式,開發者定義的容器也能被納入支援範圍。
從 1.23 版開始,for/range 可以對 function 進行迭代,這個可迭代的 function 稱為迭代器函式。迭代器函式的參數是另一個 function,依照慣例,稱為 yield 函式
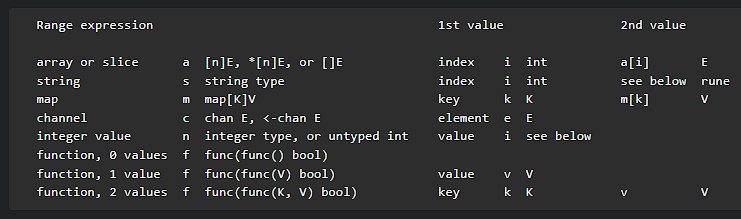
用個範例來說明,假設函式庫的開發者想讓使用者能迭代元素,它可以提供一個迭代器函式
// All is an iterator over the elements of s.
func (s *Set[E]) All() func(yield func(E) bool){
return func(yield func(E) bool) {
for v := range s.m {
if !yield(v) {
return
}
}
}
}而使用者則能使用 for/range 來迭代
for e := range set.All() {
fmt.Println(e)
}在上面的例子中,All() 回傳迭代器函式,你可能會奇怪,yield 函式在哪呢?答案是在 for/range 的兩個括號中。Go 編譯器遇到 for/range 後面接迭代器函式時,會將迴圈主體的部分,編譯成一個 func,並傳給迭代器函式。它等義於
// compile to yield func
yield := func(e int) bool {
fmt.Println(e)
return true
}
// pass to iterator func
for e := range set.m {
if !yield(e) {
return
}
}可以想像編譯器需要多做很多事來支援該語法,但使用者不需要理會複雜的實現細節,只要知道,這是個類似語法糖的設計,當 for/range 後面接 iterator 函式時,迴圈主體會被打包成 yield 函式。
true or false,這是個問題
在前面的討論中,我們提到 yield 函式會返回 bool,而迭代器可以用這個 bool 來判斷是否繼續迭代。可是,依照原本的語意,如果直接在 for/range 中 return true/false,它的作用域(scope)應該是 for/range 所在的函式,而非 yield 函式。白話點講,如果 for/range 的 statement 會被打包成 yield 函式,那當其中存在 continue / break 時,會發生什麼呢?
Taylor 的敘述有些模糊,但可以理解
When used with a for/range statement, the for/range statement will ensure that if the loop exits early, through abreakstatement or for any other reason, then the yield function will return false.
當與 for/range 陳述式一起使用時,for/range 陳述式會確保如果迴圈提前結束,無論是透過break陳述式或其他原因,yield 函式都會回傳 false。
更明確的解釋要看 rsc 在 Github 中的討論串
In fact, the Go compiler would effectively rewrite the second form into the first form, turning the loop body into a synthesized function to pass to t.All. However, that rewrite would also preserve the “on the page” semantics of code inside the loop likebreak,continue,defer,goto, andreturn, so that all those constructs would execute the same as in a range over a slice or map.
事實上,Go 編譯器會將第二種形式有效地重寫為第一種形式,將迴圈主體轉換成一個合成函式傳遞給 t.All。然而,這種重寫也會保留迴圈內部程式碼的「頁面上」語意,如break、continue、defer、goto和return,使得所有這些結構的執行結果與對切片或映射使用 range 時相同。
是的,透過編譯器的魔法,持續執行的迴圈將被視為 true,而中斷執行的迴圈則會是 false,同時,所有迴圈內的關鍵字保留原本的語意。break 意思是中斷迴圈,這會導致 yield 返回 false,進而讓迭代不再執行;而 continue,會跳過 yield 函式中沒執行的段落,開始下一次迭代。
小結:分歧的社群意見
Go 1.23 引入 iterator,讓容器可以用同樣的方式來迭代,開發者有標準可以依循,對生態系來說可能是件好事,但它同時也引發一些爭議。fasthttp 的作者 Aliaksandr Valialkin 發文指出
Go was known as easy-to-read-and-understand code with explicit code execution paths. This property breaks irreversibly in Go1.23 :( What we get in exchange? Yet another way to iterate over types, which has non-trivial implicit semantics.
Go 以易讀易懂且具有明確代碼執行路徑著稱。這一特性在 Go1.23 中被不可逆地破壞了 :( 我們換來了什麼?又一種迭代類型的方法,具有隱晦的隱式語義。
Valialkin 的批評確實有道理,如果你在閱讀 for/range 語句時跟我有同樣的困惑,覺得它太像魔法了,問題大概在於
It implicitly wraps the loop body into an anonymous function and implicitly passes this function to the push iterator function.
它隱式地將迴圈主體包裝成匿名函式,並隱式地將此函式傳遞給推送迭代器函式。
It implicitly calls the anonymous pull function and passes the returned results to the loop body.
它隱式調用匿名的 pull 函數,並將返回的結果傳遞給循環體。
It implicitly transforms return, continue, break, goto and defer statements into another non-obvious statements inside the anonymous function passed to the push iterator function.
它隱式地將 return、continue、break、goto 和 defer 語句轉換為傳遞給 push 迭代器函數的匿名函數內的其他不明顯的語句。
在程式設計領域,優美有兩種意思,一種是語意精確,能明確傳達意圖;另一種是語法簡潔,用最少字數表達複雜概念。iterator 的確讓語法顯得更簡潔,但因為它有許多隱式轉換,降低了語意的精確性。使用者通常會認為 for/range 是命令式語句,可是實際上,當它後面放置 iterator 函式時,它更像是函數式語言--要正確理解 iterator 的行為,會需要付出更多認知成本。
這篇文章中,我將 Go 的目標群眾分為「開發者」與「使用者」,這是從函式庫的角度來區分,因為兩者受到的影響有明顯差別。如果你是一名函式庫開發者,特別是跟資料結構有關的函式庫,iterator 為你帶來可供依循的方向,你將可以用更低的成本,支援更多的行為;而如果你是函式庫的使用者,可能會在閱讀時遇到一些問題,希望看完這篇文章後,能更知道該如何理解它。