Goroutine 的併發治理:管理 Worker Pool
併發會需要多個 Goroutine 來同時執行任務,Goroutine 雖然輕量,也還是有配置成本,如果每次新的任務進來,都需要重新建立並配置 Goroutine,一方面不容易管理 Goroutine 的記憶體,一方面也會消耗 CPU 的運算效能。這時 Worker Pool 就登場了,我們可以在執行前,先將 Goroutine 配置好放到資源池中,要用時再調用閒置資源來處理,藉此資源回收重複利用。這篇文章會從 0 開始建立 Work Pool,試著丟進不同的場景需求,看看如何實現。
基本的 Worker Pool
Worker Pool 的概念可以用這張圖來解釋
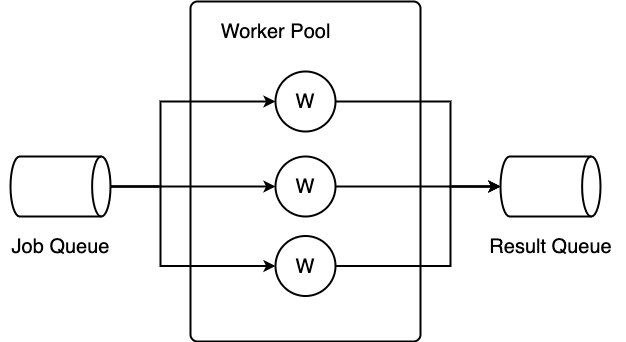
Job 會放在 Queue 中送給 Pool 內配置好的 Worker,Worker 處理完後再將結果送到另一個 Queue 內。因為這是很常見的併發模式,Go by Example 有個精簡的例子,說明 Worker Pool 如何實現
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Println("worker", id, "started job", j)
time.Sleep(time.Second)
fmt.Println("worker", id, "finished job", j)
results <- j * 2
}
}
func main() {
const numJobs = 5
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs)
for a := 1; a <= numJobs; a++ {
<-results
}
}Worker Pool 的特點是一次配置,多次執行。先建立 Worker 的 input / output channel,這裡用 jobs 跟 results。接著用 Goroutine 起好所有的 worker,並監聽 jobs 的資訊。然後就可以開始往 jobs 內丟工作,並到 results 等著接收處理完的訊息。
這段程式讓 Job 可以併發執行,但它沒經過封裝,資訊比較散,例如要修改 worker 數量的話,需要修改 numJobs 這個變數;如果希望 channel 可以 buffer 還沒處理的 job,則需要修改 jobs 初始化的命令。這些跟 Goroutine 管理相關的邏輯,可以宣告個 Worker Pool 的 struct 來集中管理。
經過封裝的 Worker Pool 變成
func main() {
pool := NewWorkerPool(10, 5)
pool.Run()
go func() {
for i := 0; i < 100; i++ {
pool.Push(i)
}
}()
pool.Wait(100)
}
type WorkerPool struct {
jobCh chan int
done chan struct{}
queueLen int
workerCnt int
}
func NewWorkerPool(queueLen int, workerCnt int) *WorkerPool {
return &WorkerPool{
jobCh: make(chan int, queueLen),
done: make(chan struct{}),
queueLen: queueLen,
workerCnt: workerCnt,
}
}
func (p *WorkerPool) Run() {
for i := 0; i < p.workerCnt; i++ {
go func(i int) {
for j := range p.jobCh {
time.Sleep(100 * time.Millisecond)
fmt.Println("worker", i, "finished job", j)
p.done <- struct{}{}
}
}(i)
}
}
func (p *WorkerPool) Push(j int) {
p.jobCh <- j
}
func (p *WorkerPool) Wait(total int) {
var cnt int
for range p.done {
cnt++
if cnt == total {
return
}
}
}我們把 input/output 兩個 channel 都放進 Worker Pool 內,並在 Run() 中配置與啟動 Goroutine,而 Push 則用來將 Job 放進 Queue 中,最後用 Wait 來等待所有任務執行完成。這與 Go by Example 的邏輯相同,只是外面用 OOP 的概念多封裝一層。
試著執行一下
worker 1 finished job 2
worker 2 finished job 1
worker 4 finished job 4
...
worker 4 finished job 98
worker 1 finished job 96
worker 2 finished job 97這邊有個有意思的問題,task number 該由 WorkPool 來管理,還是該由 main func 來管理?就我的觀點來說,有多少任務只有 Worker Pool 的調用方知道,因此讓 main func 來作這件事比較妥當。
有 Timeout 的等待
讓我們多加一些場景需求進去。假設 Worker 中可能會有長時間執行的任務,為了避免執行時間太長,超過規格容許程度。要在 Wait 時設定 timeout,超過就退出並回覆一個 timeout error。
這個需求只要活用 Go select 的能力就可以達成。什麼是 select?這是一個用來監聽 input 的命令,只要有 input 進來就會觸發後續的處理。熟悉 C 語言的工程師應該能想到 C 中的 select function,的確,兩者的語義是類似,只是 C 主要是用來監聽文件描述符,而 Go 擴大了 input 的使用範圍。讓我們多問一個問題,假設一個程序有兩個 input,兩個 input 同時有值進來,程序應該要先執行哪個 input 的值?這要回到 CSP 的定義來看
在 CSP 模型的第五點,Tony Hoare 說
If several input guards of a set of alternatives have ready destinations, only one is selected and the others have no effect; but the choice between them is arbitrary.
如果多個守護命令成立,只有一個會被執行,其他的沒有效果。但是要選擇哪個執行則是隨機。
事實上,Go 也是這麼實現的
A select blocks until one of its cases can run, then it executes that case. It chooses one at random if multiple are ready.
select 會阻塞直到其中一個 case 可以執行,當多個 case 可以執行時,則隨機選擇一個。
Tony Hoare 沒詳細解釋這樣設計的原因,但我想,這是避免 input 間存在隱性的相依關係,如果 input 的 select 是隨機的,等於說兩個 input 的地位相等。
回來看 timeout 的實現,這邊只要修改 Wait() 就可以了
func (p *WorkerPool) Wait(d time.Duration, total int) error {
var cnt int
timeout := time.After(d)
for {
select {
case <-timeout:
return errors.New("timeout")
case <-p.done:
cnt++
if cnt == total {
return nil
}
}
}
}試著執行,可以看到
worker 3 finished job 3
worker 0 finished job 0
...
worker 0 finished job 43
worker 1 finished job 44
worker 4 finished job 41
timeout
worker 4 finished job 49
worker 3 finished job 45
worker 0 finished job 47
worker 2 finished job 46
worker 1 finished job 48timeout 後,只有還在執行的 job 會被執行完,其他的就不再執行。
傳遞 Job 而不是資料
在前面的範例中,我們都是拿 i 當 input,但這是傳遞資料給 worker 處理,處理邏輯還是放在 worker 中。如果處理的邏輯改變了,原本的設計就會失敗。資料跟處理邏輯應該是兩件事,如果想讓調用端自定義 Job 處理的方式,可以怎麼做?直覺做法是類似 callback function,調用端註冊要執行的 func,等到條件符合時,註冊的 func 就會自動被調用。在 Go 語言,func 是一等公民,我們可以換個角度想,如果把 func 也當成一種值,只要把 func 丟進 Queue 中,讓 worker 自行呼叫就好了。
先來設計 Job 的樣子
type Job struct {
Fn func(int) error
}
func NewJob(fn func(int) error) Job {
return Job{
Fn: fn,
}
}
func (j *Job) Do(n int) error {
return j.Fn(n)
}NewJob 會吃進一個 func,把它包裝起來,在 worker 內,只需要用 Do() 來呼叫它
func (p *WorkerPool) Run() {
for i := 0; i < p.workerCnt; i++ {
go func(i int) {
for j := range p.jobCh {
j.Do(i)
p.done <- struct{}{}
}
}(i)
}
}而具體的邏輯,會放在 main func 內
func main() {
pool := NewWorkerPool(10, 5)
pool.Run()
go func() {
for i := 0; i < 100; i++ {
num := i
pool.Push(NewJob(func(n int) error {
time.Sleep(100 * time.Millisecond)
fmt.Println("worker", n, "finished job", num)
return nil
}))
}
}()
if err := pool.Wait(10 * time.Second, 100); err != nil {
fmt.Println(err)
}
}驗證設計
使用併發後,應該能帶來效能上的提升,但至於實際上改善多少?有沒有如同預期?會需要另外設計 Benchmark 來確認併發有沒有發揮作用。
關於 Benchmark,可以從三個面向來看,第一個是第一項任務完成時間,在一個響應式的系統中,第一項任務完成時間會關係到使用者多快可以得到回饋,好知道請求有被執行;第二個是每項任務平均完成時間,理想情況下,各任務的完成時間應該會差不多,但如果有資源阻塞的情況,就可能拉長某些任務的處理時間;第三個是全部任務完成時間,從端到端的觀點來看,代表整個請求的處理被完成。
我們把效能監控交給一個背景執行的 Goroutine 負責,稱它為 Gb,用來統計各個 Worker Pool 中各 Goroutine 的執行情況,Worker Pool 的 Goroutine 會在開始跟結束時,各送一個訊號給 Gb
startCh := make(chan int, 100)
endCh := make(chan int, 100)
pool.Push(NewJob(func() error {
startCh <- num
time.Sleep(100 * time.Millisecond)
endCh <- num
return nil
}))而 Gb 會監控這個訊號,並轉成需要的 metric,等到執行完畢時印出
func statWork(ctx context.Context, startCh chan int, endCh chan int) <-chan struct{} {
var first time.Duration
var periods []time.Duration
startTs := make(map[int]time.Time)
startTime := time.Now()
done := make(chan struct{})
go func() {
for {
select {
case n := <-startCh:
startTs[n] = time.Now()
case n := <-endCh:
period := time.Since(startTs[n])
periods = append(periods, period)
if len(periods) == 1 {
first = period
}
case <-ctx.Done():
total := time.Since(startTime)
var allPeriod time.Duration
for _, p := range periods {
allPeriod += p
}
average := allPeriod / 100
fmt.Printf("first: %v, average: %v, total: %v\n", first, average, total)
done <- struct{}{}
return
}
}
}()
return done
}另外,我們不僅想知道執行後的 metric,我們也想知道執行時的狀況是否如同預期,像是有多少 Job 正在「執行中」,又有多少 Job 已經「被完成」,因此多加一個 ticker,每 20ms 印出一次執行狀況
func statWork(ctx context.Context, startCh chan int, endCh chan int) <-chan struct{} {
ticker := time.NewTicker(20 * time.Millisecond)
var wip, cnt int
// ...
go func() {
for {
select {
case <-ticker.C:
fmt.Printf("ts: %v, wip: %d, cnt: %d \n",
time.Since(startTime),
wip,
cnt,
)
// ...
}
}
}
// ...
}先看在沒有併發的情況下,得到的結果
ts: 20.533328ms, wip: 1, cnt: 0
ts: 40.240159ms, wip: 1, cnt: 0
ts: 61.060294ms, wip: 1, cnt: 0
ts: 81.064288ms, wip: 1, cnt: 0
ts: 101.070834ms, wip: 1, cnt: 0
ts: 120.955999ms, wip: 1, cnt: 1
ts: 140.383283ms, wip: 1, cnt: 1
# ...
ts: 10.001063663s, wip: 1, cnt: 99
ts: 10.021033326s, wip: 1, cnt: 99
first: 101.164179ms, average: 100.386499ms, total: 10.039199429s第一個任務用時 101.16ms,平均 100.38ms,因為總共有 100 個 job,所以總共用了 10s 左右的時間,跟預期差不多。另外執行時的 wip 都是 1,顯示同時間只有一個 worker 在執行。
再來看有併發的結果
ts: 20.569597ms, wip: 5, cnt: 0
ts: 40.118856ms, wip: 5, cnt: 0
ts: 61.041621ms, wip: 5, cnt: 0
ts: 80.207746ms, wip: 5, cnt: 0
ts: 101.211041ms, wip: 5, cnt: 2
ts: 121.074584ms, wip: 5, cnt: 5
# ...
ts: 1.980522061s, wip: 5, cnt: 95
ts: 2.000850008s, wip: 5, cnt: 95
first: 100.971561ms, average: 99.18092ms, total: 2.003859502s第一個任務用時 100.97ms,平均 99.18ms,跟沒併發的情況差異不大,因為開了 5 個 Goroutine 去分擔 Job,全部任務完成時間縮短為 1/5,只有 2s 左右。另外執行時的 wip 都是 5,每個 worker 都有吃到工作,完成數也穩定上升,偶爾有 2 跳到 5 這樣的情況,代表每個 worker 不一定會同時完成任務。
從結果可以看出來,併發對第一項任務完成時間的幫助不大,因為本質上,併發是利用阻塞的時間處理其他事情,而第一項任務通常還不會有阻塞問題;但由於有效利用了阻塞時間,在全部任務完成時間可以得到有效提升。
最後,再看看同樣是併發,有 worker pool 跟沒有 worker pool 在效能上會差多少,這邊用 go 的 benchmark 來測試
func BenchmarkPool(b *testing.B) {
pool := NewWorkerPool(10, 5)
pool.Run()
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg := sync.WaitGroup{}
wg.Add(100)
for i := 0; i < 100; i++ {
pool.Push(NewJob(func() error {
wg.Done()
return nil
}))
}
wg.Wait()
}
}
func BenchmarkNoPool(b *testing.B) {
for i := 0; i < b.N; i++ {
wg := sync.WaitGroup{}
wg.Add(100)
for i := 0; i < 100; i++ {
go func() {
wg.Done()
}()
}
wg.Wait()
}
}執行後得到
go test -v -bench="." .
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkPool
BenchmarkPool-12 70965 16668 ns/op
BenchmarkNoPool
BenchmarkNoPool-12 58084 20715 ns/op大約能改善 22% 的效能,對計算密集的場景,應該能擠出一些運算能力。
其他人的做法
除了前面自行實現的 Worker Pool 外,也來看看其他人怎麼設計。Github 的 gammazero/workerpool 有 900+ 星星,應該具有一定的成熟度,它的 API 包含
func (p *WorkerPool) Pause(ctx context.Context)
func (p *WorkerPool) Size() int
func (p *WorkerPool) Stop()
func (p *WorkerPool) StopWait()
func (p *WorkerPool) Stopped() bool
func (p *WorkerPool) Submit(task func())
func (p *WorkerPool) SubmitWait(task func())
func (p *WorkerPool) WaitingQueueSize() int其中 Pause() 有點意思,可以讓 Goroutine 先暫停,不要執行 Job。來看看說明
Pause causes all workers to wait on the given Context, thereby making them unavailable to run tasks. Pause returns when all workers are waiting. Tasks can continue to be queued to the workerpool, but are not executed until the Context is canceled or times out.
這是怎麼辦到的呢?因為理論上,不同 input 間不會彼此影響,因此要讓 Goroutine 停止執行,就需要塞住整個 Goroutine,給它一個持續等待的 Job
func (p *WorkerPool) Pause(ctx context.Context) {
// ...
ready := new(sync.WaitGroup)
ready.Add(p.maxWorkers)
for i := 0; i < p.maxWorkers; i++ {
p.Submit(func() {
ready.Done()
select {
case <-ctx.Done():
case <-p.stopSignal:
}
})
}
// Wait for workers to all be paused
ready.Wait()
}在這個 Job 中,會用到 context 來當結束的命令,除非 context cancel 或 timeout,Goroutine 會阻塞在 ctx.Done()。阻塞 Job 的總量跟 Goroutine 最大數量相同,當一個 Goroutine 阻塞後,它就不會再收到新的 Job,因此能確保每個 Goroutine 都能被分配到一個阻塞 Job。
另一個有意思的設計是,Work Pool 可以根據需求自行 scale out 或 scale in Goroutine 的數量,這段邏輯實作在 dispatch 的 func 中
func (p *WorkerPool) dispatch() {
timeout := time.NewTimer(idleTimeout)
var workerCount int
// ...
for {
// ...
select {
case task, ok := <-p.taskQueue:
// ...
select {
case p.workerQueue <- task:
default:
// Create a new worker, if not at max.
if workerCount < p.maxWorkers {
wg.Add(1)
go worker(task, p.workerQueue, &wg)
workerCount++
}
//...
}
//...
}
}
//...
}Job 進來會直接發進 workerQueue 中,如果發不進去,表示每個 worker 都在忙碌,這時先確認當前的 worker 量是否小於最大值,如果是,起一個新的 Goroutine 來幫忙處理 Job。
至於要回收的話,看 select 的另一條分支
func (p *WorkerPool) dispatch() {
timeout := time.NewTimer(idleTimeout)
//...
for {
//...
select {
//...
case <-timeout.C:
if idle && workerCount > 0 {
if p.killIdleWorker() {
workerCount--
}
}
idle = true
timeout.Reset(idleTimeout)
}
}
//...
}有個 timer 會每 2s 起來看一次,如果這時發現沒有任務執行,而且 worker 的量大於 0,就送出結束訊號,讓 worker 停止。這樣可以降低記憶體的使用,讓閒置的 worker 不要占用資源。
小結
Worker Pool 透過資源的重複利用,降低 Goroutine 配置與回收的次數,在高併發的場景中,算是個常見的模式。儘管 Worker Pool 的好處很明顯,我還是會建議在優化前,先確認系統的效能瓶頸在哪裡,例如,如果是個 IO Bound 的系統,採用 Worker Pool 可能不一定有幫助;但如果是個 CPU Bound 的系統,採用 Work Pool 應該能降低 CPU 的壓力。
這篇放進「驗證設計」一節,也是因為寫一寫突然好奇,花功夫設計完一套機制,能帶來多少改善?在單純只看 Goroutine 配置的情況下,我的實驗是 22% 的提升,但如果加入實際的 Job 內容,還能有同樣的改善幅度嗎?我猜在 GC 壓力很大的情況下,效益應該會變得更明顯,反過來說,如果平常也不太會有 GC,Worker Pool 可能也不是必須的。
希望看完這篇文章,能讓大家在設計或選擇 Worker Pool 時更有方向。
Reference
- Go by Example: Worker Pools
- Concurrency in Go
- Implementing a worker pool
- Handling 1 Million Requests per Minute with Go
- Explain to me Go Concurrency Worker Pool Pattern like I’m five
- gammazero/workerpool: Concurrency limiting goroutine pool
- panjf2000/ants: 🐜🐜🐜 ants is a high-performance and low-cost goroutine pool in Go